

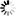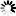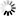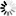
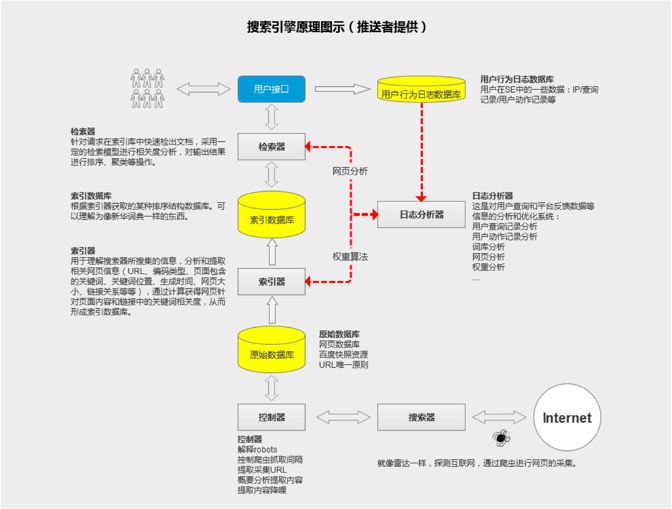
由上图搜索引擎的排名原理流程图可以看出:搜索引擎是有多个数据库系统结合一些列计算程序组合而成的庞大的计算系统。通过搜索器,SE放出大量的爬虫进行互联网页面信息的采集,在通过控制器将采集数据提取和存储,放置于原始数据库中;再通过索引器将原始数据进行归类和排序,形成索引数据库;当用户进行查询时,又通过检索器在索引数据库中进行内容提取,并依据日志分析器等系统性的判断给到用户一个依照相关度进行的排序列表,从而形成了用户的查询结果页。
要系统性的了解搜索引擎的原理,我们主要从以下几个点切入:
搜索器和控制器
搜索器主要负责互联网网页采集(即网络爬虫-蜘蛛的作用)、内容提取以及定期更新策略的执行。
互联网上的信息存储在无数个服务器上,任何搜索引擎要想回答用户的搜索,首先要把网页存在自己本地的服务器上,这靠的就是网络爬虫。它不停的向各种网站发送请求,将所得到的网页存储起来。那么爬虫怎么知道往哪发送请求呢?通常的做法是利用网页之间的链接从一个网页出发,提取出指向其他页面的链接,把它们当成将下次要请求的对象,不停重复这个过程。
这里其实有很多细节要被考虑,比如:避免循环链接的网页、解析网页文档提取里边的链接、当链接无法打开时对错误进行处理等。
爬虫爬取的网页存储后,控制器将网页的内容提取出来,并将这些信息送入原始数据库。如何高效的爬取数据也是一个很大的挑战。比如需要有成千上万个爬虫程序同时爬取数据,高效的将数据存储起来以便之后分析等。这种分布式程序的实现是一个相当大的工程。为此,控制器还需定期的进行爬取策略的更新,用已提高爬取效率和节约流量成本。
索引器
用于理解搜索器所搜集的信息,分析和提取相关网页信息(URL、编码类型、页面包含的关键词、关键词位置、生成时间、网页大小、链接关系等等),通过计算获得网页针对页面内容和链接中的关键词相关度,从而形成索引数据库。
索引是帮助程序进行快速查找的。大家都用过新华字典。字典前边的按照偏旁部首查字的部分就是索引。搜索引擎也一样。这里要介绍第一个最重要的数据结构:反转列表(inverted list)。
搜索引擎所拥有的文档中出现的每一个单词都拥有一个反转列表。它记录了这个单词在多少文档中出现,分别是哪些文档,每个文档分部出现多少次,分别出现在什么位置等信息。比如Apple这个词出现在文档1,7,19,34,102。其中文档1中出现了3次,分别在位置20,105,700。这样当用户搜索Apple时,搜索引擎就不用遍历所有的文档,只需要查找每个单词对应的反转列表就可以知道这个词在哪里出现了。每一个网络文档不仅只有文本信息。它还可能包括URL、文件名、引用等部分。为了提高搜索质量,搜索引擎需要对文档的不同部分分别处理,构造反转列表。每一部分的单词都要被加入到这个词属于此部分的反转列表里。
当然,索引系统中还包含很多其他的重要数据结构,都是为了提高用户查询结果的反馈效率,具体的内容大家可以去相关数据或搜索引擎查询获取。本培训稿不做过多解释。
检索器
检索器的功能是针对用户的查询请求在索引库中快速检出文档,采用一定的检索模型进行文档与查询的相关度分析,对输出结果进行排序、聚类等操作,并实现某种用户相关性反馈机制。
